
Announcing Gen II: Merlin’s Second-Generation Generative AI Platform
Any File, Any Task, Any Volume, Any Language and Any Place.
By John Tredennick and Dr. William Webber
We are excited to announce the upcoming release of Gen II, our second-generation GenAI platform. We released the first generation of our multi-LLM-integrated DiscoveryPartner platform in early November of last year. No, not to beta, or limited release, or with an announcement that it is coming “real soon now.” Rather and perhaps unexpectedly, as a production release to real clients.
Gen I: Advanced RAG Architecture
Our initial deployment was the first and still the only multi-LLM system in the legal market. It allows users to choose from different Large Language Models (e.g. Claude and GPTfor different tasks and price points. Gen I was the first and only system to summarize documents before synthesizing and reporting against them, which allowed users to analyze as many as 300 documents at a time (rather than being limited to an answer based on four or five documents selected by the vendor’s system). And, it then synthesized across hundreds of summaries using one of the GPT 4 series to do this work.
We offered Claude Instant (100 k) for document summaries because Claude Instant was about 50 times faster and 50 times less expensive than GPT 4 (32k). And, we put our users in the driver’s seat, allowing them to use our lightning-fast Sherlock Machine Learning algorithms to find and choose the relevant documents to be analyzed. Indeed, you could load our special Analyze folders with hundreds of documents and let GEN AI review and rank each to determine which were most responsive to a particular topic of inquiry.
Here is an example of DiscoveryPartner’s ability to quickly summarize 100 documents (using Claude Instant) and then send them to GPT 4 for synthesis and analysis–with the whole process taking about four minutes.
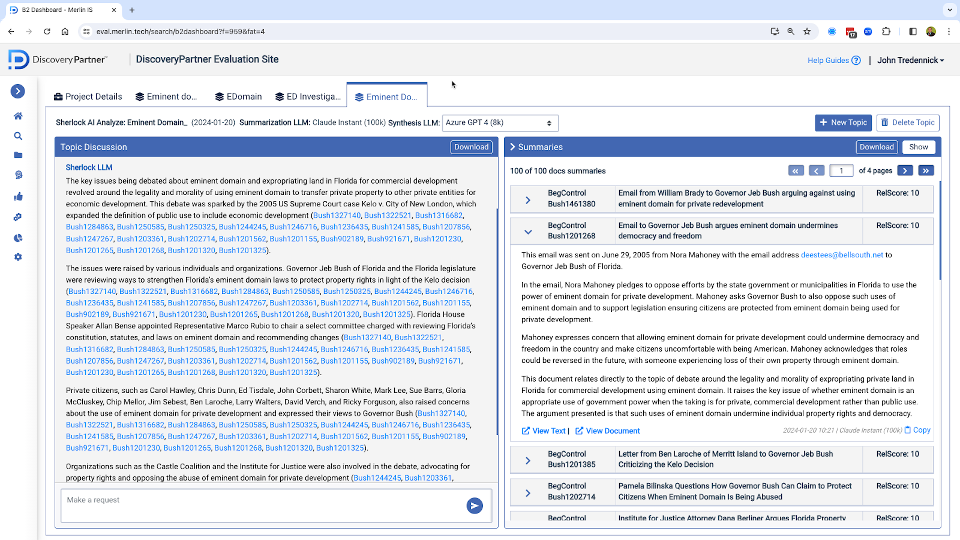
Gen I version of DiscoveryPartner showing summarization and analysis of 100 documents.
Gen I was the first and so far only platform with these capabilities. But we didn’t stop there.
Gen II: Scalable Enhanced RAG Architecture for all types of files.
By December, we were working on a second generation of the platform, one that allowed us to address several key components in Gen I that we thought could be improved with another round of development. Gen II offers almost limitless scalability, along with the ability to handle multiple file types–from large and small documents to transcripts, text messaging, medical records and even articles and reports.
We’ve done it and are just implementing it in DiscoveryPartner. Here is a quick summary of the exciting new features included in Gen II.
1. Chunking: Automatically Breaking Large Documents into Sections
With Gen I we summarized documents before sending them for synthesis. When we started working with transcripts, larger text volumes and even medical records, we realized that we had to break the documents into smaller sections. This was required in order to properly capture a lot of different information for initial search, our summaries and ultimately for answering questions. Once we saw how effective this was for transcripts, we decided to section all large documents regardless of form.
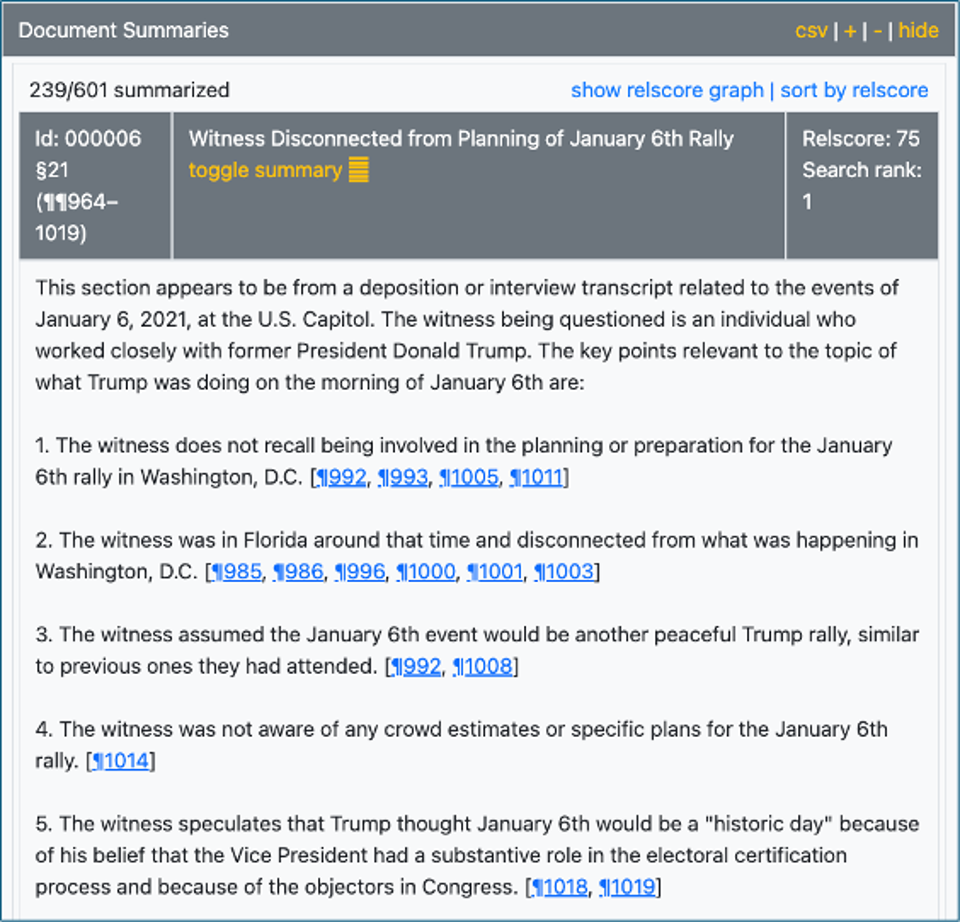
Gen II showing a section of a January 6th House Investigation Transcript.
The benefit is that Gen II can handle any type of unstructured text file from email, to large files, to transcripts, to chat messaging (IM), to medical records, and even lengthy financial reports. You can put different types of documents in different folders for analysis. Or put them all in one folder. Gen II will handle them either way.
2. Dividing Sections into Paragraphs
Our next step was to create internal paragraph references within the sections that could be linked to specific statements in the summary. The goal here was to make it easier to find relevant passages in the underlying section text. We highlight the relevant paragraphs. Like this result when I clicked on paragraph 14 in the summary and saw the relevant text below:
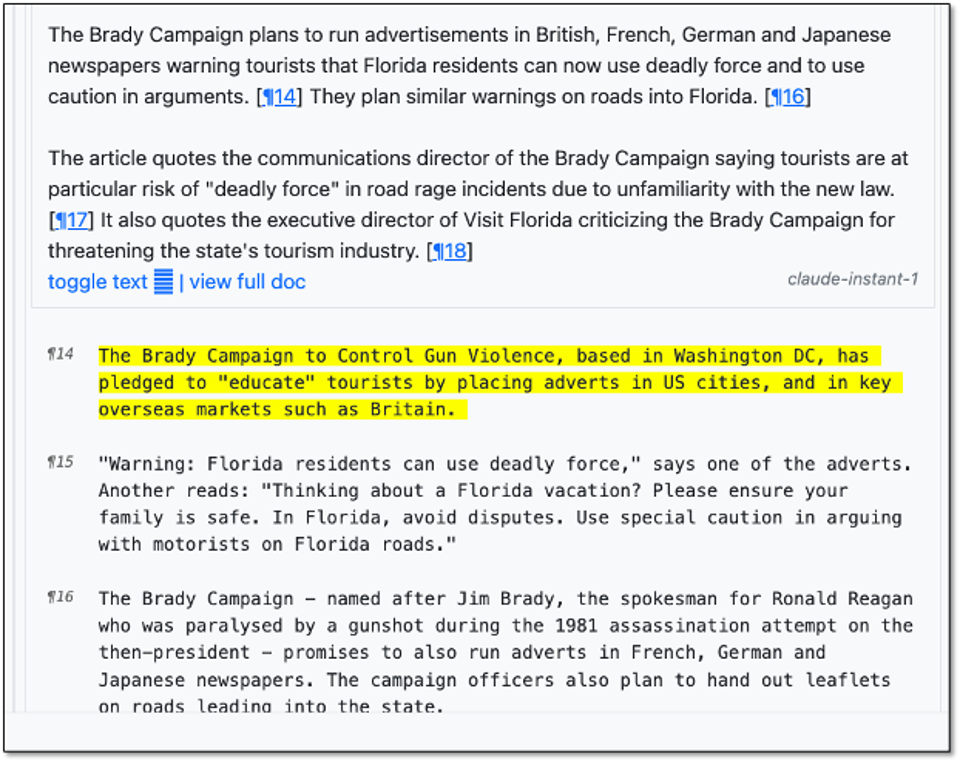
Gen II showing links between summary and native text for email file.
No special formatting is required, prior to loading, even for larger documents, text messaging / Chat, medical records or even transcripts.
3. Running Searches Before Creating Summaries
Perhaps the most important architectural change is this. When you start a new topic, we don’t automatically summarize all the documents in the folder. Instead, we have devised a powerful new search method which combines natural language search with algorithmic (ranked keyword) search that can instantly search through the document sections (remember, we are breaking large documents into sections) and surface the most relevant ones for summarization and review.
Why two kinds of searches? Because we have found that each methodology has its strengths and weaknesses. NLP converts document text into vectors for a mathematical type of search (with the topic statement also being converted). It can be effective in surfacing documents that don’t have matching keywords but are about the same concept. But, it seems less effective when your initial topic focuses on certain keywords or names.

Summaries of Chinese Medical Research Documents (100 found and summarized out of 3,000)
We found that combining the rankings for both types of searches (using a proprietary weighting we developed) was pretty effective at surfacing the most relevant sections for analysis. And, we have plans to take this even further with an additional technique that for patent reasons I can’t disclose yet but should be available in Gen II.
Why is this important? Because this will allow you to load thousands of documents in an Analyze folder (rather than a few hundred). You can analyze and report on a variety of different topics without being forced to summarize and re-summarize the entire population with each new topic. Rather, we will use our multi-layered search system to bring back your top candidates for summarization from the much larger pool.
We recognize that this sets the stage for asking questions against the entire document population, literally asking and getting answers from millions of documents. However, that functionality won’t make it into Gen II, but it will be on our development plan for future sprints.
4. Extending the Inquiry
This is clearly the second most important feature in Gen II. Many of you know that a key architectural limitation of all Large Language Models is that they can only read and analyze a limited amount of text in one go. The limit is the size of the “Context Window.” In our articles and webinars we liken the context window to a whiteboard. The prompt we send goes on the whiteboard, which the LLM can read (but never remember or share). The LLM then responds to the topic question by writing on that whiteboard. When the answer is returned to the user, the whiteboard is erased
Early versions of ChatGPT were limited to about 3,000 tokens (2500 words) on the whiteboard. That has quickly evolved to 8, 16, 32, 100 and even 200k of tokens (Claude has just released a new version with 200,000 tokens and a claim that it will go up to 1 million tokens). The key point is this: Even with these larger context windows, you still won’t be able to load all your documents into the LLM for analysis at one time.

So, we created an important workaround. Imagine that you create a topic and receive an answer based on the top 100 summaries (possibly out of thousands of documents). The answer seems on target but you find yourself wondering if there might be more information deeper in the results set, e.g. in the next 100 sections from the ranking. With Gen I, there wasn’t an easy way to find out. You might have 500 documents in a folder but the LLM can only read 200 of the summaries. What to do?
That was the reason for our Extend functionality. Simply click on “Extend” and the system will read and summarize the next XXX document sections in the rankings, synthesize/analyze across them and report on any new information you can find. If indicated, you can invoke multiple extensions until you have the information you need or, at least, there seems to be no further novel information in your document set on that topic.
From here you can easily ask the LLM to consider all of its preceding answers (original plus one or more extended answers) and prepare a comprehensive report across all of them. In this fashion, we have worked around a key architectural limitation inherent in Large Language Models.
5. Search Results Graph
For our careful readers who have reached this point, you might ask this question: How do I know when to extend my analysis? How deep do I need to go? How do I know that there is no more important information on my topic in my document set?
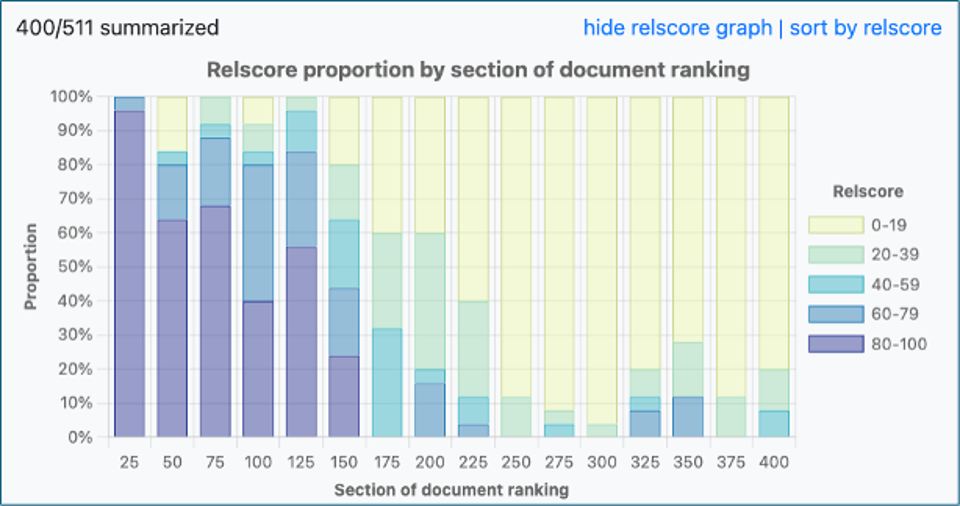
This is a tough but important question. In Gen II we set out to help our more advanced users with this question through the addition of this Relscore chart (accessible from the summaries list).
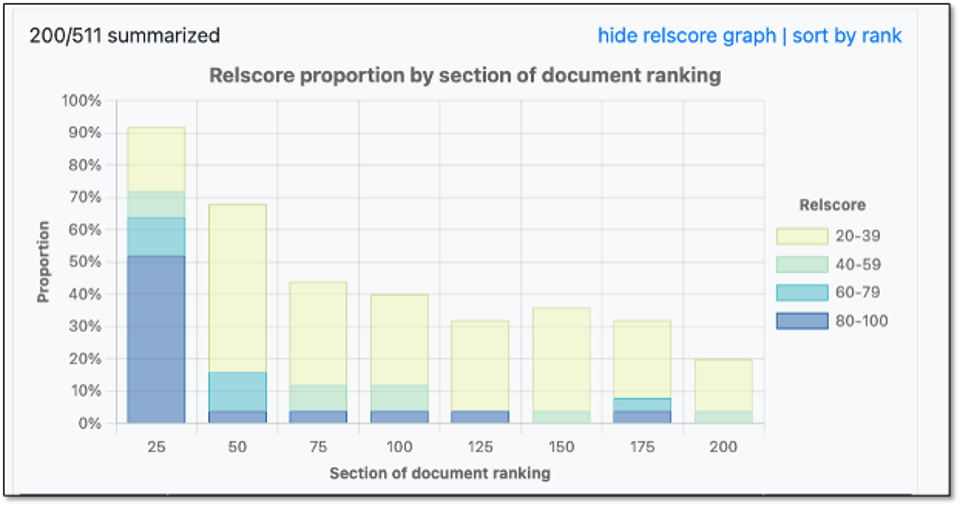
Gen II relevance score chart suggesting that extended search has found most of the relevant files.
What’s going on here? We start with the search ranking. In this case we have summarized and reported on the top 200 results out of 511 sections. We used the first 100 results for the original answer and then extended the answer to cover the second batch of 100 documents. All 200 have been ranked by GPT 4 Turbo (which is like having a human review and rank each document returned from your search).
What we see is that the first 25 documents returned from our search were highly relevant to our topic (as rated by GPT 4 Turbo). We see that about 65% of the first 25 documents returned from our initial search were highly relevant (a rating of 60 is our relevance cutoff). We can also see that the relevance rate dropped significantly in the second batch of 25 and indeed in each of the next groups as well. Interestingly there were some highly relevant documents coming in the next to the last grouping but few in the last three groups.
What might this mean? It suggests to me that the user (me in this case) found many of most of the relevant documents on our topic (“stand your ground” in this case). I could have extended my inquiry further but it seems likely that there won’t be many more documents in this folder that will help me better understand and analyze my topic.
Just for Fun: I did a further extension on this topic, asking the LLM to pull up the next 100 documents to see if there might be more information. Here is the answer I got:
EXTENDING (2): “Stand Your Ground” — All documents concerning a Florida bill permitting the use of deadly force to protect one’s self or one’s property. DP Based on the new summaries provided, there is no novel information directly related to a Florida bill permitting the use of deadly force to protect one’s self or one’s property, specifically concerning “Stand Your Ground” laws. The documents cover a wide range of topics, including environmental regulations, property rights disputes, homeowners association issues, legislative actions on various bills, and public concerns addressed to Governor Jeb Bush. However, none of these documents directly discuss “Stand Your Ground” laws or bills permitting the use of deadly force for self-defense or the defense of property. Several documents discuss property rights and regulatory issues, such as disputes over environmental regulations affecting property owners (Document 134972), concerns about homeowners association governance (Document 185712, Document 154898, Document 154958 §1), and legislative actions on various bills (Document 233584). However, these topics do not align with the specific request for information on “Stand Your Ground” legislation. |
Gen II Relevance Ranking chart suggesting that no further extensions required for topic analysis.
Any File, Any Task, Any Volume, Any Language and Any Place?
Gen II solves these issues with a new search and analyze architecture. Why Any File . . . ?
- Any File: Our Gen II architecture allows us to load any type of file (documents, emails, transcripts, SMS/IM chat, medical records, construction files, diagrams, articles, reports and more).
- Any Task: Gen II can understand and assist with a wide variety of tasks, from finding, summarizing, and reviewing relevant documents, transcripts, text, and medical records to creating timelines, witness kits, and investigation reports.
- Any Volume: Gen II combines natural language and algorithmic search, taking you from prompt to reviewing relevant documents in seconds – across literally any volume of documents.
- Any Language: Gen II allows you to read and analyze documents in over 40 major languages. Multi-language teams can all work from the same document set, each conversing in their native language.
- Any Place: Gen II comes with our unique single-tenant DiscoveryPartner architecture, allowing you to securely host documents and data in your home country or region – anywhere you can find an AWS data center.
Experience the power of Gen II for yourself. Contact us to schedule a demo of DiscoveryPartner and see how our innovative AI architecture can transform your data discovery and analysis workflows.
Gen II represents a significant leap forward in our mission to harness the power of Large Language Models for legal applications. By addressing key limitations in Gen I and introducing innovative new capabilities, we have created a platform that is more scalable, versatile, and effective at surfacing relevant information from vast troves of unstructured data.
The ability to automatically chunk large documents into sections, divide those sections into paragraphs, and link them to specific statements in the summary provides unprecedented granularity and context for analysis. Our powerful new search method, which combines natural language search with algorithmic search, enables users to quickly surface the most relevant sections from thousands of documents without the need to summarize the entire population for each new topic.
Perhaps most excitingly, the Extend functionality allows users to dig deeper into the search results, uncovering additional relevant information that might otherwise have been missed due to the limitations of LLM context windows. And with the Search Results Graph, advanced users can now make informed decisions about when to extend their analysis and how deep to go based on the relevance ratings of the returned documents.
Gen II sets the stage for even more ambitious developments in the future, such as the ability to ask questions against entire document populations numbering in the millions. While that functionality won’t make it into this release, we are confident that the architectural changes and new features in Gen II will provide our users with an unparalleled tool for navigating the complex world of legal discovery.
As always, we remain committed to pushing the boundaries of what is possible with generative AI in the legal domain. With Gen II, we have taken another significant step towards realizing that vision, and we look forward to continuing to innovate and iterate in partnership with our clients.

John Tredennick, CEO and founder of Merlin Search Technologies
JT@Merlin.Tech

Dr. William Webber, Merlin Chief Data Scientist
WWebber@Merlin.Tech
Transforming Discovery with GenAI
Take a look at our research and Generative AI platform integration work on our GenAI Page.